在实际的文件系统中,用的是 B + 树或其变形。有关性质与操作类似与 B_树。
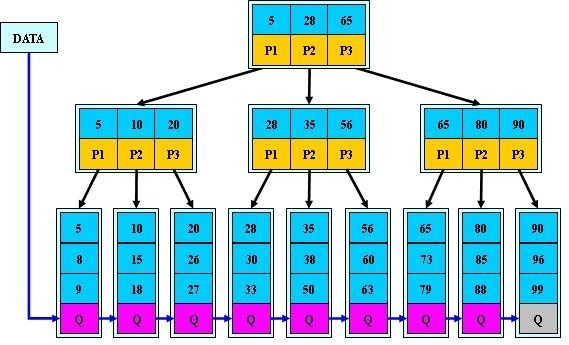
差异:
- 有 n 棵子树的结点中有 n 个关键字,每个关键字不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有叶子结点中包含全部关键字信息,及对应记录位置信息及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。(而 B 树的叶子节点并没有包括全部需要查找的信息)
- 所有非叶子为索引,结点中仅含有其子树根结点中最大(或最小)关键字。 (而 B 树的非终节点也包含需要查找的有效信息)
- 非叶最底层顺序联结,这样可以进行顺序查找
B + 特性
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层
- 更适合文件索引系统
- B + 树插入操作的平均时间复杂度为 O(logn),最坏时间复杂度为 O(logn)
查找过程
- 在 B+ 树上,既可以进行缩小范围的查找,也可以进行顺序查找;
- 在进行缩小范围的查找时,不管成功与否,都必须查到叶子结点才能结束;
- 若在结点内查找时,给定值≤Ki, 则应继续在 Ai 所指子树中进行查找
插入和删除的操作:类似于 B_树进行,即必要时,也需要进行结点的 “分裂” 或“合并”。
为什么说 B+tree 比 B 树更适合实际应用中操作系统的文件索引和数据库索引?
-
B+tree 的磁盘读写代价更低
- B+tree 的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对 B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说 IO 读写次数也就降低了。
- 举个例子,假设磁盘中的一个盘块容纳 16bytes,而一个关键字 2bytes,一个关键字具体信息指针 2bytes。一棵 9 阶 B-tree(一个结点最多 8 个关键字) 的内部结点需要 2 个盘快。而 B + 树内部结点只需要 1 个盘快。当需要把内部结点读入内存中的时候,B 树就比 B + 树多一次盘块查找时间 (在磁盘中就是盘片旋转的时间)。
-
B+tree 的查询效率更加稳定
- 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B 树和 B + 树都是平衡的多叉树。B 树和 B + 树都可用于文件的索引结构。B 树和 B + 树都能有效的支持随机检索。B + 树既能索引查找也能顺序查找.